Deep learning object detection on dental x-rays
As the interest in AI and deep learning keeps growing, we see more and more practical applications, especially in healthcare where breakthroughs could be revolutionary. I teamed up with Dr Arthur Fourcade, an oral surgeon who made his thesis on CNNs applied to medical imagery. Our first project was to work on panoramic dental x-rays and apply a few models as a proof of concept.
Our goals included:
- Build a model that can identify the tooth official index. This is a classification task, and will be the subject of another article.
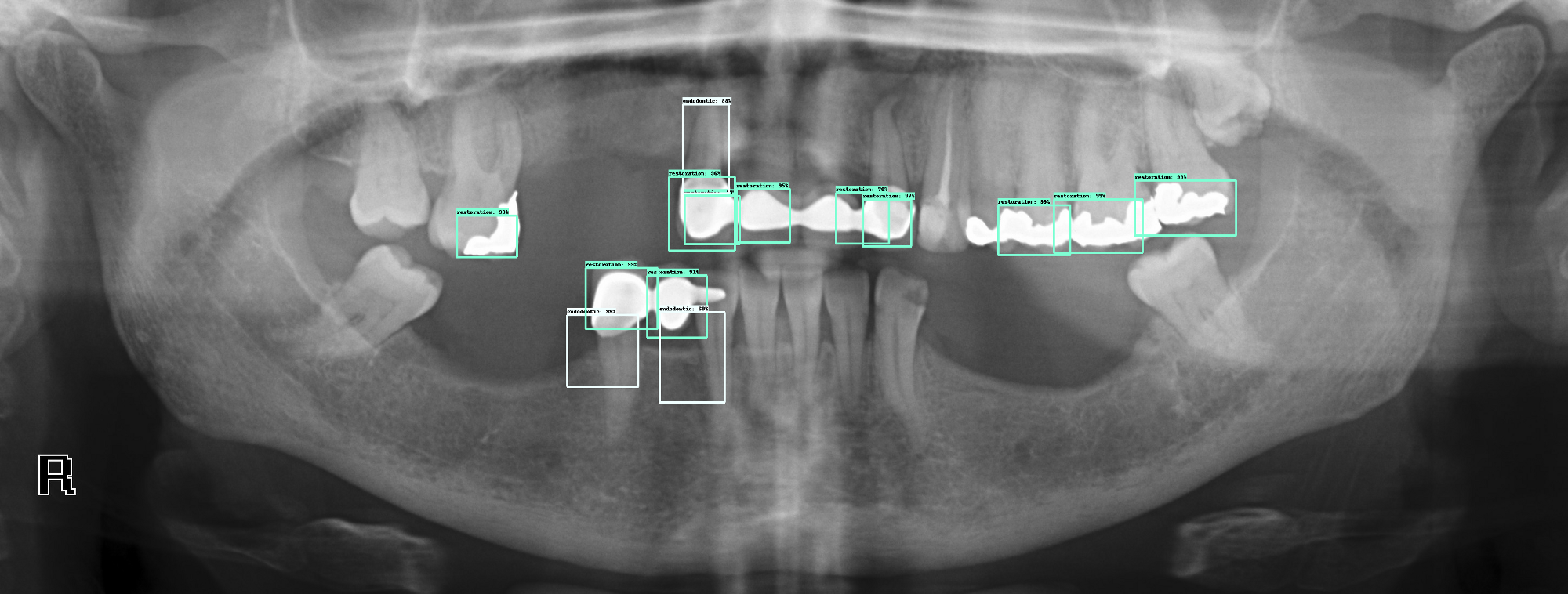
- Build a model that can detect restorations, endodontic treatments and implants on a full dental x-ray. This is an object detection task.
- See how these models compare to humans.
The idea was not to make a software that would replace doctors at all, but to build a proof of concept that could add a second opinion and could make reporting easier for doctors.
I chose to use Tensorflow Object Detection API because of its simplicity and plug-and-play approach. The idea was to prototype quickly.
Dataset
Dr Arthur Fourcade annotated a dataset of more than 500 dental panoramic x-rays, using the VoTT open-source software. There are other labeling softwares like labellmg, but VoTT was fine for the task we needed. You can export the labels under various formats, including the Tensorflow PASCAL VOC. Dr Fourcade used various datasets of dental x-rays he built during his career. The annotated dataset is not currently open sourced, but will hopefully be soon.
Dataset features:
- Every x-ray has been anonymized for privacy protection reasons, there is no way for me to trace back to any individual.
- More than 500 panoramic x-rays annotated
- Average size of x-ray: 2900 * 1400 px
- Classes: 933 endodontic, 2331 restorations and 145 implant occurrences. The number of implant occurrences is a bit low and makes it quite hard for the model to detect implants in an evaluation dataset. This can be countered with data augmentation techniques.
Preprocessing
Preprocessing is the main task before training the model with Tensorflow Object Detection API. You need to save the images and classes under a specific format. The setup tutorial proposed here is very clear and proposes some excellent examples: https://github.com/tensorflow/models/tree/master/research/object_detection
You can find my pre-processing code here:
https://github.com/clemkoa/tooth-detection/blob/master/data_preprocessing.py
Model
Several data augmentation are needed for this task, but we used mainly vertical and horizontal flips, as well as random black patches and random contrast adjustments.
I used mainly two models: FastRCNN and SSD_mobilenet_v1. I wanted to compare both models on this very specific task. I used them out of the box and I have made little modifications so far.
We are dealing with very big images (high resolution) where all the classes are quite similar, that is why an out-of-the-box model might not be fully suited for this task. My goal was to see how well it would perform, to establish a baseline for future improvements. Comparing FastRCNN and SSD was also an objective.
I started training on my laptop to prototype, but I ended up training everything on Google Cloud platform.
We chose SSD_mobilenet_v1 for our final model because it ended up giving a better accuracy. Most effort was spent on region proposal features, especially non-max suppression thresholds and number of proposals. As there are 32 teeth max per x-ray, we can fine-tune the region proposal numbers. Results
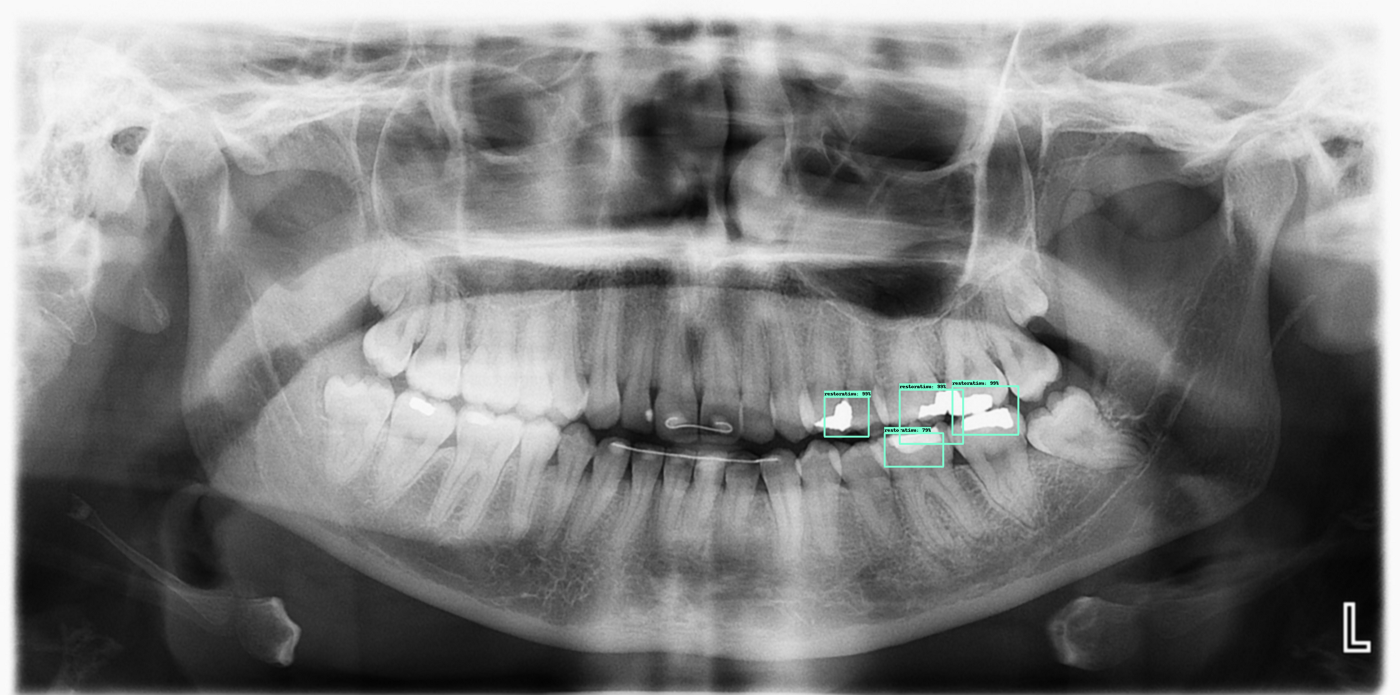
Here are some of the result outputs we have so far:
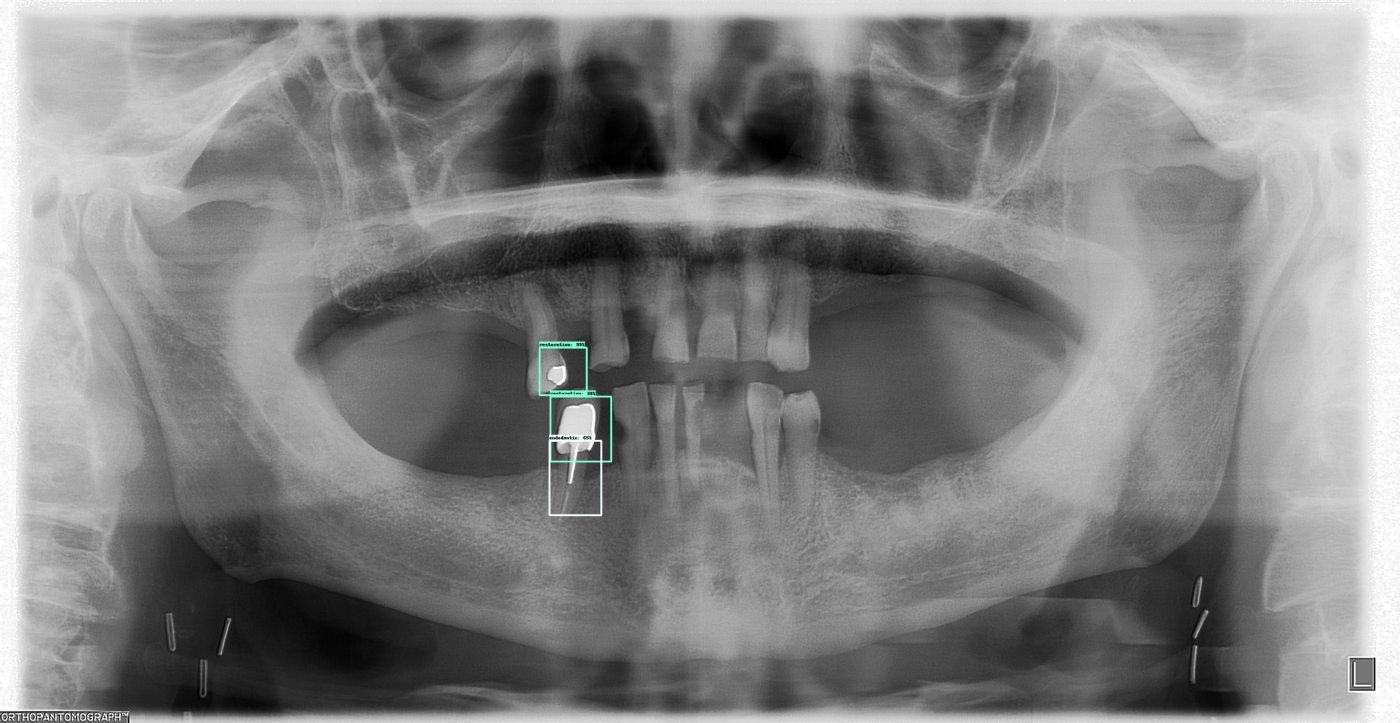
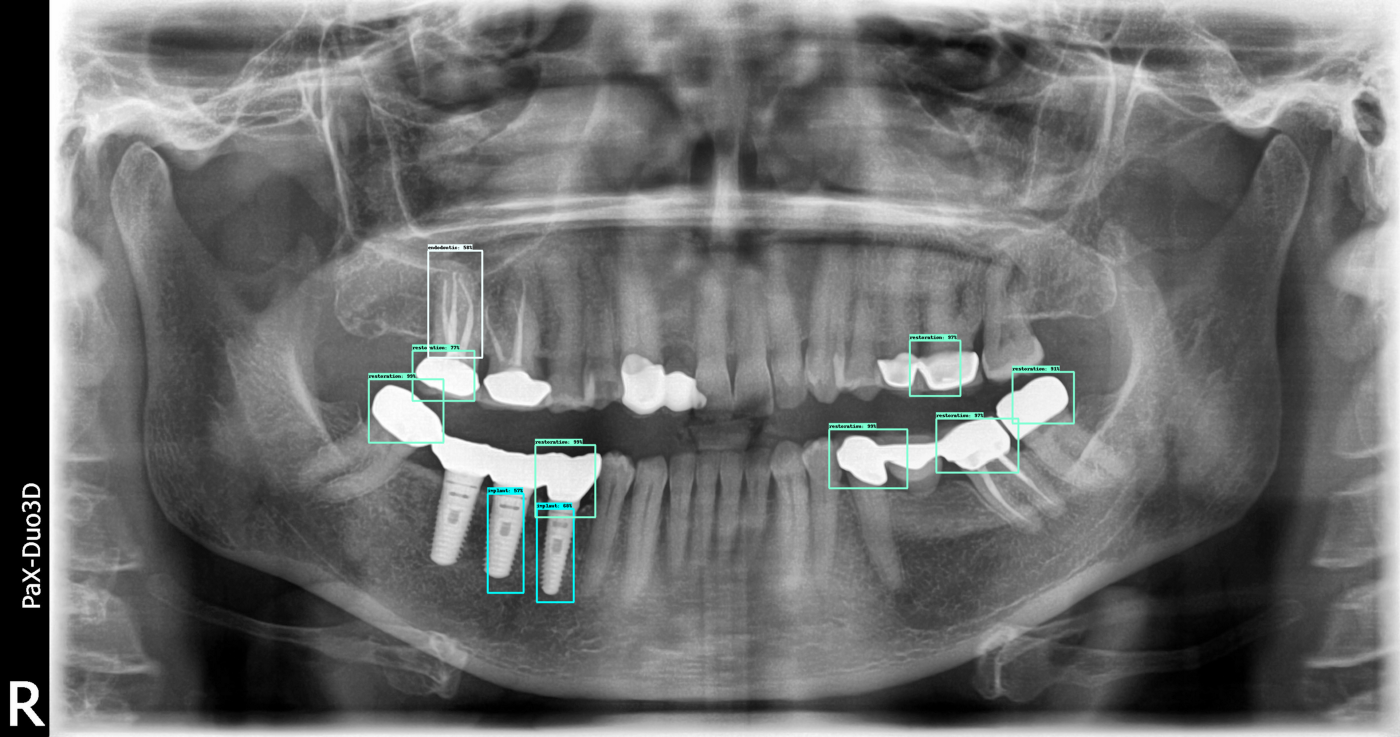
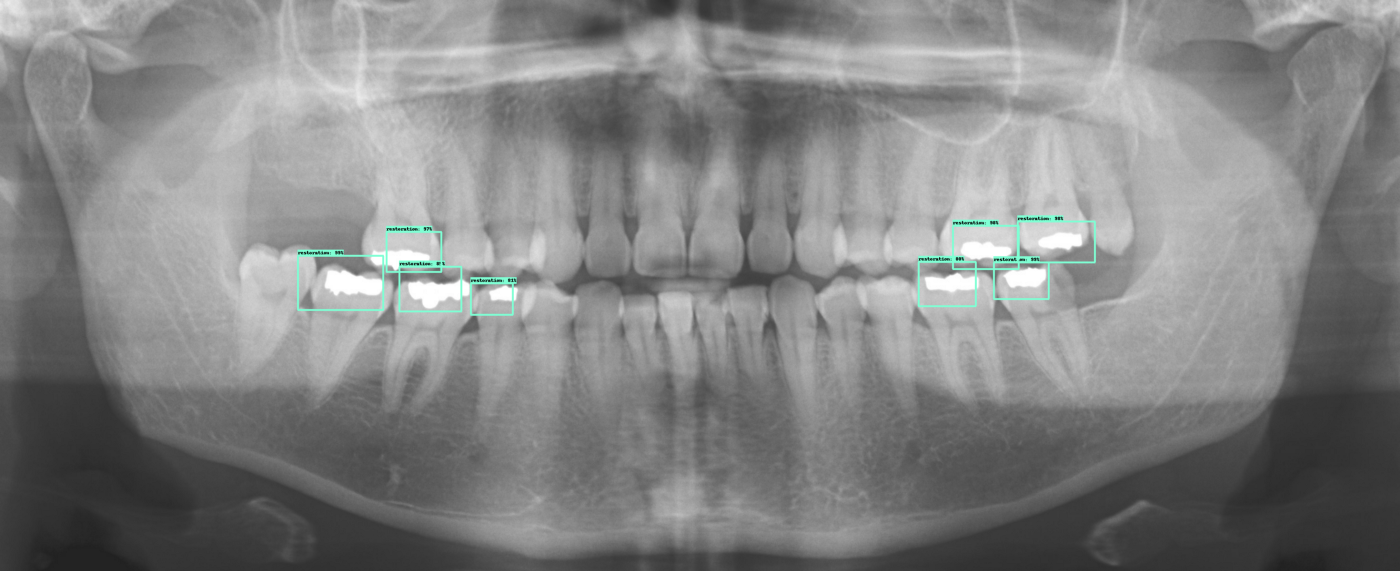
An example where the model is not working as well as intended
You can find the code, without the dataset at the moment, here: https://github.com/clemkoa/tooth-detection
We are still working on this project, trying to improve accuracy as it was only a prototype. Any feedback is welcome!